
Google I/O, one of the most anticipated events in the tech industry, never fails to captivate audiences with its groundbreaking announcements and innovations. This year’s conference, Google I/O 2024, was no exception, as the tech giant unveiled a plethora of new features, updates, and initiatives across various domains. Let’s delve into the highlights and key takeaways from this year’s event.

Firebase Genkit:
Google has added Firebase Genkit to its Firebase platform, enabling developers to build AI-powered applications in JavaScript/TypeScript. Genkit, using the Apache 2.0 license, enables developers to quickly build AI into new and existing applications. It supports content generation, summarization, text translation, and image generation. The Firebase team promises that developers can use Genkit as part of the Firebase toolchain, allowing them to test new features locally and deploy their applications using Google’s serverless platforms. Genkit already supports third-party open source projects, vector databases, embedders, evaluators, and other components through its plugin system. Project IDX, Google’s next-gen web-based integrated developer environment, will support Genkit’s developer UI out of the box. Firebase Data Connect, powered by Google’s Cloud SQL Postgres database, is also available.
Let’s dive into the biggest ones:
Google’s AI presentation at Google I/O 2024 was a standout, with the corporation mentioning AI 121 times. CEO Sundar Pichai praised the company’s efforts to count AI, which was outstanding for a 110-minute presentation. Google is integrating Gemini, an LLM-based platform, into its Android, Search, and Gmail products. This comes after OpenAI announced their GPT, which stirred controversy. At WWDC, Apple is also anticipated to announce a partnership with OpenAI to integrate its technology into its own products. The talk emphasized the importance of AI in the IT business.
Generative AI for Learning:

Google has created LearnLM, a collection of generative AI models designed to “conversationally” instruct students on a variety of topics. LearnLM is already utilized in several Google products, including YouTube, Google’s Gemini applications, Google Search, and Google Classroom. Google is collaborating with educators to explore how LearnLM might simplify and improve lesson planning, assisting teachers in discovering new ideas, information, and activities. LearnLM also powers Circle to Search on Android, a function that assists with fundamental arithmetic and physics problems, as well as a tool on YouTube that allows users to ask clarifying questions, receive explanations, or take quizzes based on what they’re seeing. LearnLM will allow users to develop bespoke chatbots that may serve as subject matter experts, delivering study help and practice activities in Google’s Gemini apps.
Quiz Master:
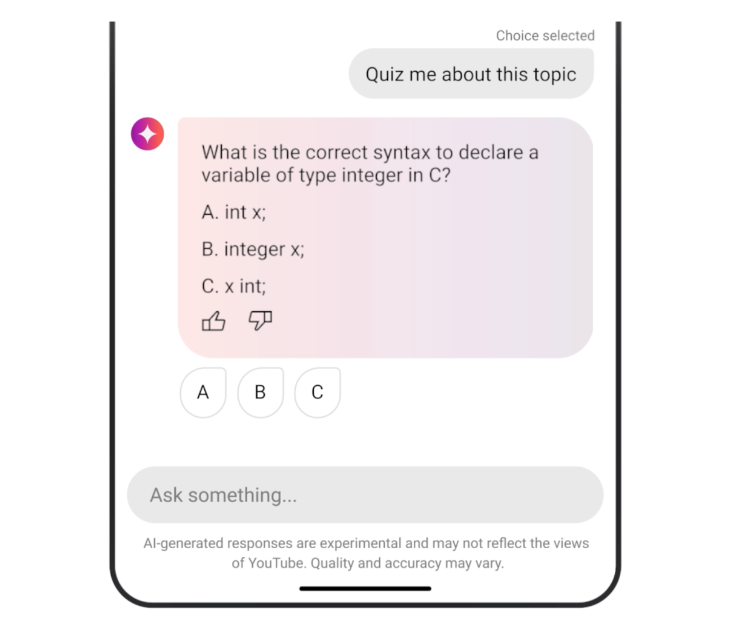
Google has released AI-generated quizzes on YouTube, allowing users to ‘raise their hand’ as they watch educational videos. Users can utilize the conversational AI tool to ask clarifying questions, receive explanations, and take subject-specific quizzes. The Gemini model’s long-context capabilities make it ideal for lengthier videos such as lectures or seminars. The new features are now available to select Android users in the United States, after YouTube’s initial experimentation with AI-generated quizzes on its mobile app. The new features are designed to create a more personalized and engaging learning experience for YouTube’s educational material.
Gemma 2 Updates:

Google has announced the release of Gemma 2, the second version of their open-weight Gemma models, with a 27 billion parameter model due to be available in June. The model, the Gemma family’s first vision language model, is already available in pre-trained versions for picture captioning, labeling, and visual Q&A applications. The conventional Gemma machines, which debuted earlier this year, were offered in 2-billion-parameter and 7-billion-parameter configurations. According to Josh Woodward, Google’s VP of Google Labs, the Gemma models have been downloaded millions of times across various services, and the 27-billion model has been tuned to run on Nvidia’s next-generation GPUs, a single Google Cloud TPU host, and the managed Vertex AI service. Google hasn’t released much data.
Scam Busters: Detect Scams During Calls:
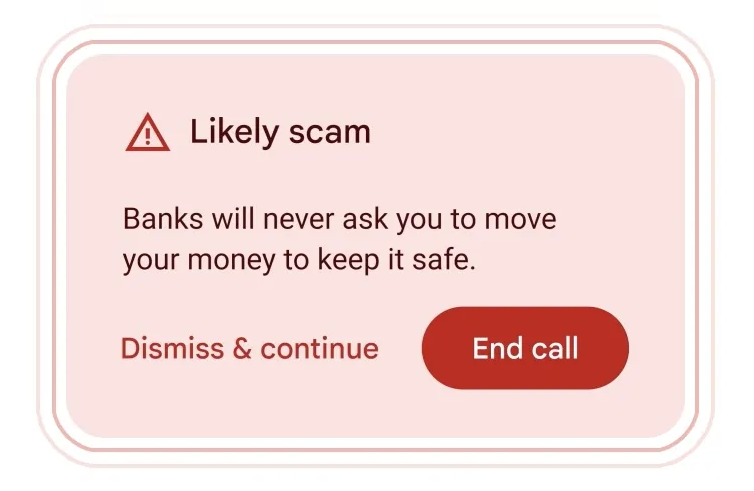
Google has demonstrated a service that would alert customers to potential scams during phone calls using Gemini Nano, the smallest form of Google’s generative AI offering. The capability will be added to a future version of Android and will listen for “conversation patterns commonly associated with scams” in real time. It will initiate classic fraudster tactics such as password demands and gift cards, which are known methods of obtaining money from consumers. Once activated, the feature will display a warning that the user may be falling victim to unscrupulous people. There is no definite release date for the function, but it is opt-in, which means the system will not automatically upload to the cloud. This function raises concerns among privacy, but it may not be available to everyone.
Ask Your Photos Anything: Ask Photos:
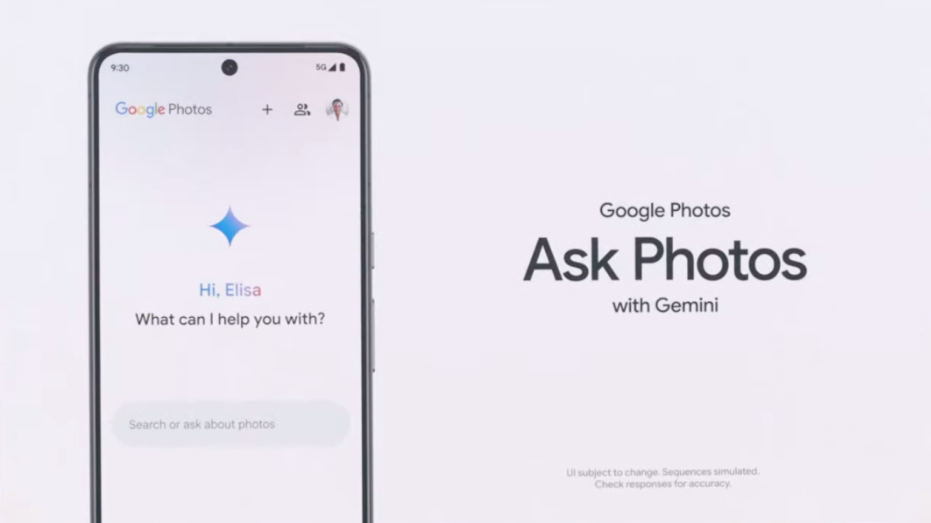
Google Photos is introducing an experimental feature named “Ask Photos”, powered by Google’s Gemini AI model. This feature allows users to search their photo collection using natural language queries. The AI’s ability to comprehend photo content and metadata makes it easier to find relevant content, reducing the need for manual searches. Users can instruct the AI to perform more complex tasks, such as identifying the “best photo from each of the National Parks I visited.” Ask Photos complements the recently launched Photo Stacks feature, which groups near-duplicate photos and employs AI to highlight the best ones within the group.
The “Ask Photos” feature also allows users to ask questions and receive useful responses, such as identifying the finest photos from a vacation or other groups. The AI can also use its multimodal ability to determine whether a photo has text that is related to the question. The function will be available in English in the United States first, followed by other markets. It may become increasingly deeply integrated over time as Gemini runs on the device. Google claims that users’ personal information in Google Photos is not used for advertising or to train any other generative AI product.
All About Gemini:
Google provided an in-depth overview of Gemini, its innovative ecosystem of productivity tools and services designed to empower users to work smarter and more efficiently. From email management and document collaboration to project planning and communication, Gemini offers a seamless and integrated experience across the entire Google ecosystem.
Boosting Gmail with Gemini:

At the Google I/O 2024 conference, Google announced that Gmail users will soon be able to use its Gemini AI technology to search, summarize, and draft emails. This new feature will also help with e-commerce returns by searching inboxes, finding receipts, and completing online forms. Users can also have Gemini summarize recent emails, examine attachments, and arrange receipts. However, there are still concerns about how AI is trained and how users’ data is handled, so it’s not yet clear how widely this new feature will be adopted. Gemini will also be able to write emails and provide highlights from meetings in Google Meet. A paid upgrade called Gemini 1.5 Pro will be available in Workspace Labs.
Gemini 1.5 Pro:
Google has a new version of its big language model. It can handle more information, like longer documents and videos. This helps the model understand data better and give more helpful answers. Developers who want to try this new model can sign up on Writer Team Studio. Along with the bigger context, the new model has also been improved in different ways. It can now generate better code, reason more logically, and have conversations that go back and forth. It can also understand audio and images. For tasks that don’t need as much power, Google is making a smaller model called Gemini 1.5 Flash. This model is good for things like summarizing text, making chatbots, and writing captions for images and videos.
Gemini Live:
Google is enhancing its AI-powered chatbot Gemini to better understand the world around it and the people conversing with it. At the Google I/O 2024 developer conference, Google previewed a new experience called Gemini Live, which allows users to have in-depth voice chats with Gemini on their smartphones. Users can interrupt Gemini while the chatbot is speaking to ask clarifying questions, and it will adapt to their speech patterns in real time. Gemini Live is in some ways the evolution of Google Lens and Google Assistant. The technical innovations driving Live stem from Project Astra, a new initiative within DeepMind to create AI-powered apps and “agents” for real-time, multimodal understanding. Gemini Live can answer questions about things within view of a smartphone’s camera, explain computer code, or suggest which skills to highlight in an upcoming job or internship interview. It is also designed to serve as a virtual coach, helping users rehearse for events, brainstorm ideas, and provide information more succinctly and answer more conversationally than text-based interactions.
Gemini Nano:

Google has announced that it will build Gemini Nano, the smallest of its AI models, directly into the Chrome desktop client starting with Chrome 126. This will enable developers to use the on-device model to power their own AI features, such as the existing “help me write” tool from Workspace Lab in Gmail. The company claims that recent work on WebGPU and WASM support in Chrome enables these models to run at a reasonable speed on a wide set of hardware. Google is in talks with other browser vendors to enable this or a similar feature in their browsers. Google’s bet is to enable a number of high-level APIs in Chrome to translate, caption, and transcribe text in the browser using its Gemini models. The company’s vision is to give users the most power AI models in Chrome to reach billions of users without worrying about prompt engineering, fine-tuning, capacity, and cost.
Android Gets a Gemini Boost:
Google’s Gemini on Android, an AI replacement for Google Assistant, will integrate with Android’s mobile operating system and Google’s apps. At the Google I/O 2024 developer conference, the company announced that users will be able to drag and drop AI-generated images directly into their Gmail, Google Messages, and other apps. YouTube users will be able to tap “Ask this video” to find specific information from within a YouTube video. Gemini Advanced subscribers will have the ability to use an “Ask this PDF” option, which allows users to get answers from documents without having to read through all the pages. Gemini on Android can also generate captions on photos, ask questions about articles, and perform other generative AI tasks. However, OpenAI’s GenAI model, GPT-4o, will work with text, speech, and video, including the phone’s camera.
Maps Get Smart: Gemini on Google Maps:
Google is introducing Gemini model capabilities to its Maps Platform, starting with the Places API. Developers can now display generative AI summaries of places and areas in their apps and websites, based on insights from over 300 million contributors. This eliminates the need for developers to create custom descriptions of places. The new summaries are available for various types of places, such as restaurants, shops, supermarkets, parks, and movie theaters. Google is also introducing AI-powered contextual search results for the Places API, allowing developers to display reviews and photos related to users’ searches. These results are available globally and will be expanded to more countries in the future.
Tensor Processing Units Get a Performance Boost:
Google has announced the sixth generation of Tensor Processing Units (TPU), Trillium, at its Google I/O developer conference. The sixth generation, dubbed Trillium, will launch later this year, featuring a 4.7x performance boost in compute performance per chip compared to the fifth generation. This is achieved by expanding the chip’s matrix multiply units (MXUs) and pushing the overall clock speed. Google has doubled the memory bandwidth for Trillium chips and added the third generation of SparseCore, a specialized accelerator for processing ultra-large embeddings in advanced ranking and recommendation workloads. The new chips are described as Google’s “most energy-efficient” TPUs yet, addressing the growing demand for AI chips. Google promises that the new TPUs are 67% more energy-efficient than the fifth-generation chips. Google’s TPUs come in various variants, but no additional details or pricing details have been provided. Developers will have to wait until early 2025 to access the next-gen Blackwell processors.
AI in Search:
Google is introducing AI-powered overviews to its users in the US, aiming to counter concerns about losing market share to competitors like ChatGPT and Perplexity. The company has built a custom Gemini model for search, combining real-time information, Google’s ranking, long context, and multimodal features. The AI overviews are expected to be available to over a billion people by the end of the year. Google has been testing AI-powered overviews through its Search Generative Experience (SGE) since last year, and the feature is more useful for complex queries and scattered information. Google is also using Gemini as an agent for tasks like meal or trip planning, organizing search results pages with different elements based on the query. The company is aiming to make its search results page more dynamic to address these concerns.
GenAI:

Google has announced plans to use generative AI to organize search results pages, in addition to the existing AI Overview feature. The AI Overview feature will become available on Tuesday after a stint in Google’s AI Labs program. The new search results pages will be shown when users are looking for inspiration, such as visiting Dallas for an anniversary trip. They will also show results when users search for dining options and recipes, with more results for movies, books, hotels, shopping, and more. Google plans to use generative AI to organize the entire results page, understand the topic, and recognize users’ needs. The company is also aiming to expand the use cases it can help users with, such as solving complex questions, integrating them with products, and helping them more deeply. This move could potentially lead to the death of SEO.
Veo:
Google is launching Veo, an AI model that can create 1080p video clips around a minute long given a text prompt. Veo builds on Google’s preliminary commercial work in video generation, which tapped the company’s Imagen 2 family of image-generating models to create looping video clips. It appears to be competitive with today’s leading video generation models, including Sora, Pika, Runway, and Irreverent Labs.
Demis Hassabis, head of Google’s AI R&D lab DeepMind, said that the company is exploring features like storyboarding and generating longer scenes to see what Veo can do. Veo was trained on lots of footage, which works with generative AI models: Fed example after example of some form of data, the models pick up on patterns in the data that enable them to generate new data — videos, in Veo’s case.
Eck described Veo as “quite controllable” in the sense that it understands camera movements and VFX reasonably well from prompts. It also supports masked editing for changes to specific areas of a video and can generate videos from a still image, a la generative model like Stability AI’s Stable Video.
Veo will remain behind a waitlist on Google Labs, the company’s portal for experimental tech, for the foreseeable future, inside a new front end for generative AI video creation and editing called VideoFX. As it improves, Google aims to bring some of the model’s capabilities to YouTube Shorts and other products.
Generative AI Upgrades:

Google has announced Imagen 3, the latest in its Imagen generative AI model family, at its I/O developer conference in Mountain View. CEO Dimitri Hassabis said that Imagen 3 is more accurate in understanding text prompts and produces fewer distracting artifacts and errors. It is also the best model yet for rendering text, which has been a challenge for image-generation models. To address concerns about deepfakes, Google will use SynthID, an approach developed by DeepMind to apply invisible, cryptographic watermarks to media. Sign-ups for Imagen 3 in private preview are available in Google’s ImageFX tool, and the model will be available soon to developers and corporate customers using Vertex AI. Google typically doesn’t reveal much about the source of data used to train its AI models, as much of the training data comes from public sites and datasets.
Circle to Search:

Google has announced that its Circle to Search feature, which allows Android users to get instant answers using gestures like circling, will now be able to solve more complex problems across psychics and math word problems. The new capabilities are made possible thanks to Google’s new family of AI models for learning, LearnLM. Circle to Search is designed to make it more natural to engage with Google Search from anywhere on the phone by taking actions like circling, highlighting, scribbling, or tapping. It will now be able to handle problems with symbolic formulas, diagrams, graphs, and more. Since launching earlier this year, Circle to Search has expanded to more Samsung and Google Pixel devices, making it available to more than 100 million devices.
Project IDX:
Google has announced Project IDX, its next-gen AI-centric browser-based development environment, is now in open beta. Launched as an invite-only service in August, the platform has already attracted over 100,000 developers. Google aims to help solve the complexities of deploying AI as it becomes more prevalent. Project IDX offers a multi-platform development experience with easy-to-use templates for various frameworks and languages. It also includes integrations with Google Maps Platform, Chrome Dev Tools, Lighthouse, Cloud Run, and Checks, Google’s AI-powered compliance platform. IDX also includes features like code completion, chat assistant sidebar, and generative fill, similar to Photoshop. It also integrates with GitHub and has built-in iOS and Android emulators for mobile developers. The development environment is expected to be available from beta to general availability on Tuesday.
All Images Credits: Google / Google CEO Sundar Pichai at the Google I/O 2024 event
Do You Need more information?
For any further information / query regarding Technology, please email us at info@varianceinfotech.in
OR call us on +1 630 534 0223 / +91-7016851729, Alternately you can request for information by filling up Contact Us
 Please wait...
Please wait...
Leave a Reply